系统运行日志
关键活动
查看关键活动列表
| 字段 | 说明 |
|---|---|
| 发生时间 | |
| 操作 | |
| 对象 | |
| 子对象 | |
| 运行结果 |
搜索关键活动
| 字段 | 说明 |
|---|---|
| 操作类型 | |
| 发生起止时间 |
操作类型说明
| 字段 | 说明 |
|---|---|
| ScalingReplicaSet | |
| SuccessfulCreate | |
| Pulled | |
| Killing | |
| SuccessfulDelete | |
| Created | |
| Scheduled | |
| Started | |
| Pulling | |
| NodeHasSufficientMemory |
异常结束
查看异常结束列表
| 字段 | 说明 |
|---|---|
| 发生时间 | |
| 异常原因 | |
| 对象 | |
| 子对象 | |
| 异常分析 |
搜索异常结束事件
| 字段 | 说明 |
|---|---|
| 操作类型 | |
| 发生起止时间 |
异常告警
告警接收人配置:通过站内信发送告警信息给指定用户(系统管理员通过管理>网站配置>系统配置>全局变量配置> warning_user_ids,配置接收的用户id)
以下异常原因将触发通知:
| 字段 | 通知内容 |
|---|---|
| Unhealthy | 不触发通知 |
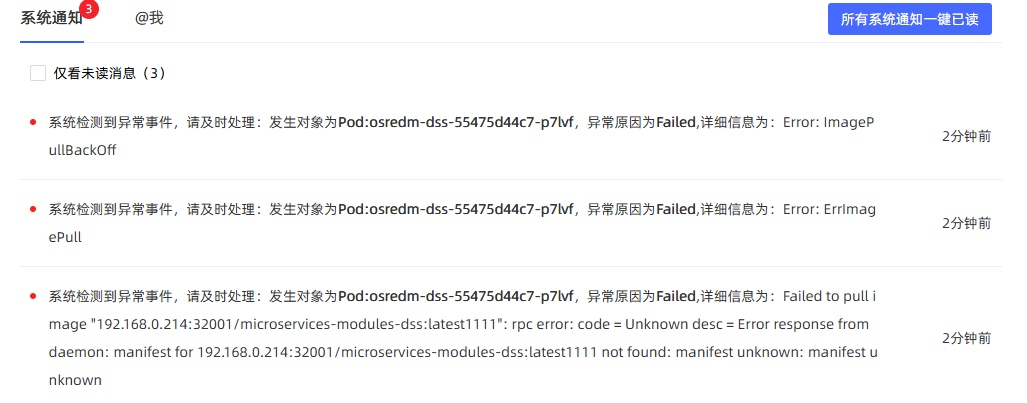
| Failed | 系统检测到异常事件,请及时处理:发生对象为{xxxx},异常原因为Failed,详细信息为:{xxxx} |
| FailedKillPod | 系统检测到异常事件,请及时处理:发生对象为{xxxx},异常原因为FailedKillPod,详细信息为:{xxxx} |
| BackOff | 系统检测到异常事件,请及时处理:发生对象为{xxxx},异常原因为BackOff,详细信息为:{xxxx} |
| FailedPostStartHook | 系统检测到异常事件,请及时处理:发生对象为{xxxx},异常原因为FailedPostStartHook,详细信息为:{xxxx} |
| FailedScheduling | 系统检测到异常事件,请及时处理:发生对象为{xxxx},异常原因为FailedScheduling,详细信息为:{xxxx} |
| FailedCreatePodSandBox | 系统检测到异常事件,请及时处理:发生对象为{xxxx},异常原因为FailedCreatePodSandBox,详细信息为:{xxxx} |
| FailedToUpdateEndpointSlices | 系统检测到异常事件,请及时处理:发生对象为{xxxx},异常原因为FailedToUpdateEndpointSlices,详细信息为:{xxxx} |
Unhealthy异常原因触发示例
Unhealthy(不健康):这通常指的是 Pod 的 Readiness 或 Liveness 探针失败。
- 产生原因:
- Liveness Probe 失败:Kubelet 根据你定义的 liveness probe 规则(如 HTTP GET 请求、TCP Socket 或 Exec 命令)判断容器是否还“活着”。如果连续失败次数超过阈值,Kubelet 会认为容器已经“死掉”,并重启该容器。
- Readiness Probe 失败:Kubelet 根据你定义的 readiness probe 规则判断容器是否已经准备好接收流量。如果失败,Kubernetes 会将该 Pod 从关联的 Service 的负载均衡端点中移除,确保不会有流量被发送到这个不健康的 Pod。
- 触发示例
系统管理员在管理>运维管理>集群管理>定制化编排页面,选择一个服务(以数据统计服务(osredm-dss)为例),编辑配置文件,修改“健康检查路径(readinessProbe)”为一个不存在的路径
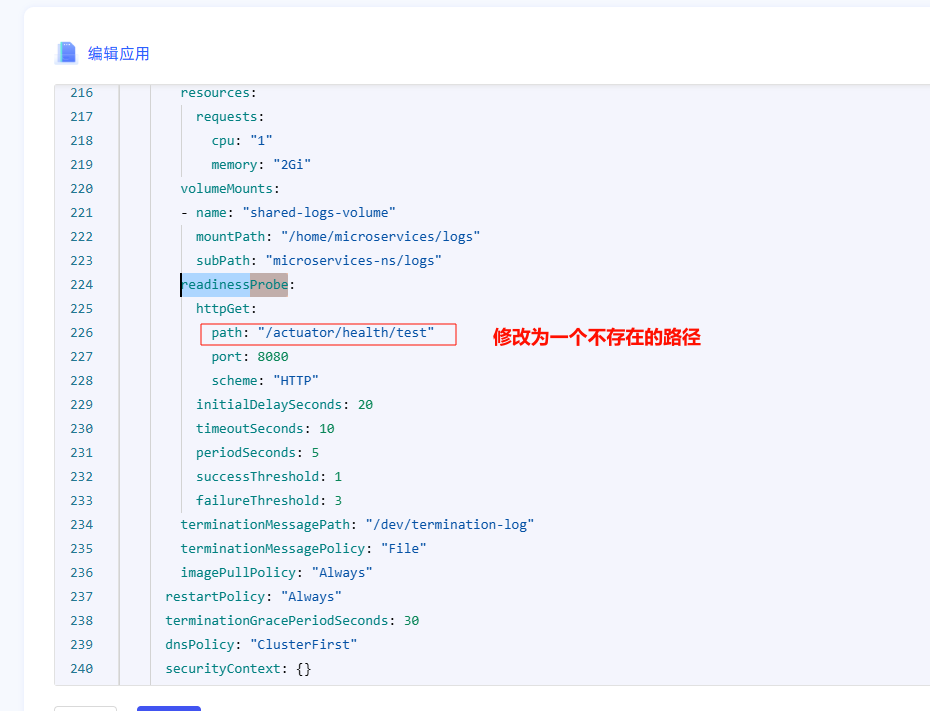 等待1-2分钟,将会触发异常:
等待1-2分钟,将会触发异常:

Failed异常原因触发示例
Failed(失败):这个状态非常直接,它表示 Pod 中的一个或多个容器已经终止运行,且至少有一个容器是以失败(非零)的状态退出的。
- 产生原因:
- 容器内的主进程崩溃并返回了非零退出码。
- 镜像本身有问题,无法启动(例如,找不到指定的启动命令)。
- 资源限制(如内存不足 OOMKilled)导致容器被系统杀死。
- 触发示例:
系统管理员在管理>运维管理>集群管理>定制化编排页面,选择一个服务(以数据统计服务(osredm-dss)为例),编辑配置文件,修改其镜像为一个错误的地址
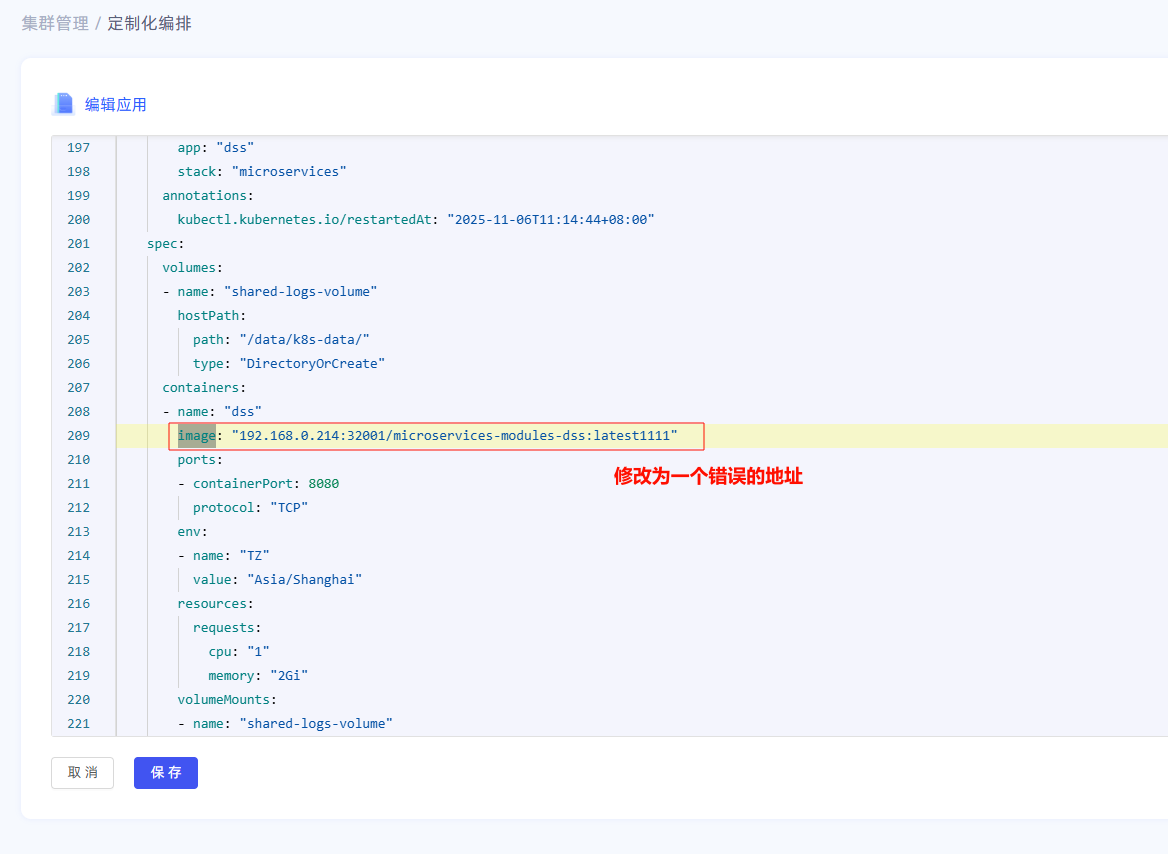
等待1-2分钟,将会触发异常:
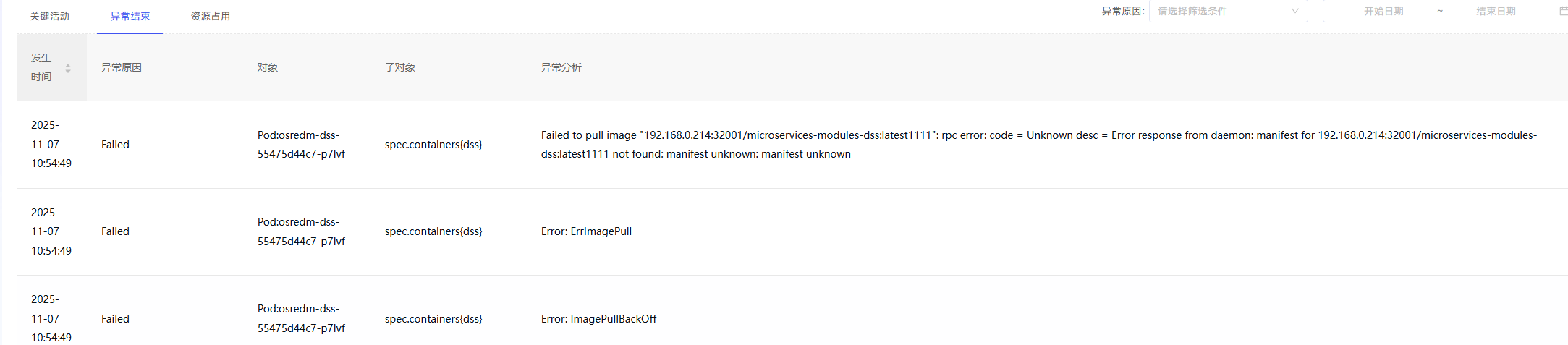
异常告警接收用户将收到告警通知:
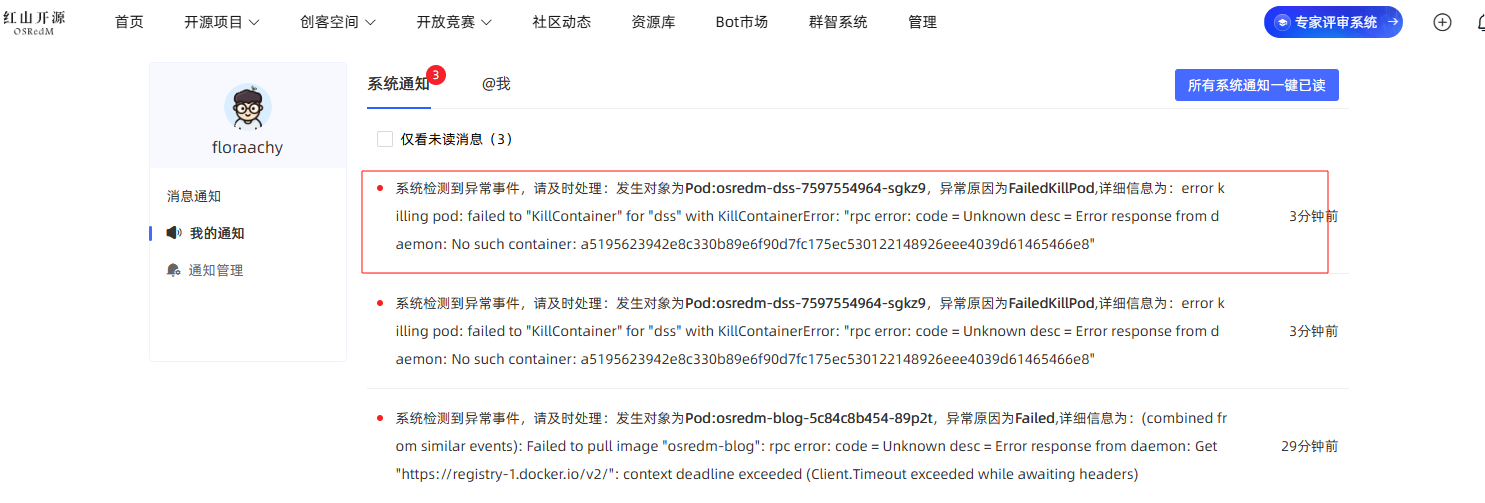
FailedKillPod异常原因触发示例
FailedKillPod(杀死 Pod 失败): 当 Kubernetes 系统(通常是 kubelet)试图终止一个 Pod 但失败时,会出现此错误。
- 产生原因:
- 容器进程变成了“僵尸进程”或陷入“无法中断的睡眠”状态(D 状态),无法响应 SIGTERM 信号。
- 节点本身状态异常(如内核崩溃、硬盘故障),导致 kubelet 无法正常执行清理操作。
- 存储卷卸载失败,导致 Pod 无法被完全清理。
- 触发示例:
系统管理员在管理>运维管理>集群管理>定制化编排页面,选择一个服务(以数据统计服务(osredm-dss)为例),编辑配置文件,修改有问题的存储卷以及创建无法卸载的存储
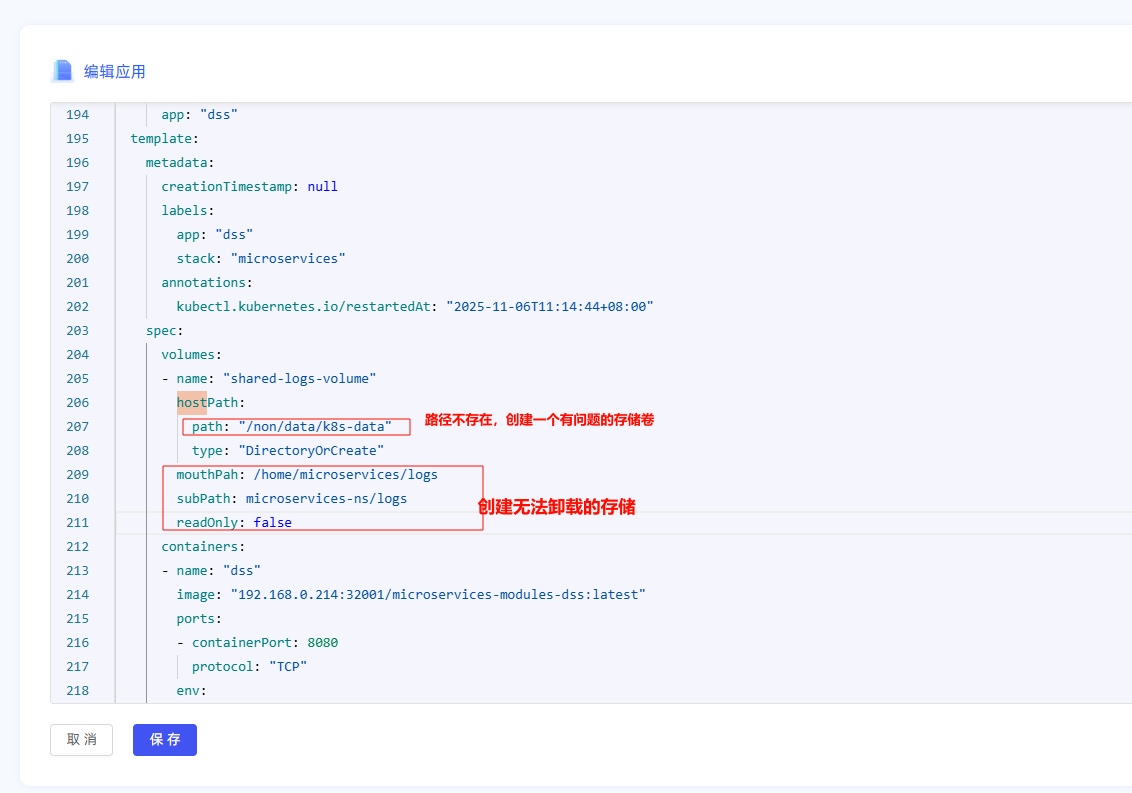
等待1-2分钟,将会触发异常:

异常告警接收用户将收到告警通知:
BackOff(回退)
BackOff(回退):这个状态通常是 CrashLoopBackOff 的一部分。它表示容器不断启动失败,并且 Kubernetes 正在使用指数退避算法来延迟下一次重启尝试,以避免消耗过多资源。
- 产生原因:
- 根本原因与 Failed 相同(容器启动后立即退出)。Kubernetes 会不断重启它,但每次失败后,重启的间隔会越来越长(10秒,20秒,40秒…直到最多5分钟)。
FailedPostStartHook(PostStart 钩子执行失败)
FailedPostStartHook(PostStart 钩子执行失败): PostStart 钩子是在容器创建后立即执行的一段代码或命令。如果这个钩子执行失败(返回非零退出码),Kubernetes 会杀死这个容器。
- 产生原因:
- 钩子中执行的命令不存在。
- 命令执行失败(例如,权限不足、访问的网络资源不可用)。
- 钩子运行超时。
FailedScheduling(调度失败)
FailedScheduling(调度失败):这是最常见的异常之一,表示 Scheduler(调度器)无法为 Pod 找到一个合适的节点来运行。
- 产生原因:
- 资源不足:没有节点拥有足够的 CPU 或内存来满足 Pod 的请求(requests)。
- 节点选择器/亲和性不匹配:Pod 的 nodeSelector 或 nodeAffinity 规则与任何节点的标签都不匹配。
- 污点和容忍度:节点上有 Pod 无法容忍的污点(Taint)。
- 其他:持久卷声明无法绑定、节点端口冲突等。
FailedCreatePodSandBox
产生原因 这个事件发生在 kubelet 无法为 Pod 创建沙箱环境时。Pod 沙箱是容器运行时的基础环境。
常见原因:
- 容器运行时故障:Docker/containerd 服务异常
- 镜像拉取失败:网络问题或镜像不存在
- 资源不足:磁盘空间不足、内存不足、PID 限制等
- 网络插件问题:CNI 配置错误或网络资源耗尽
- 安全策略限制:Pod Security Policy 或 SELinux 限制
FailedToUpdateEndpointSlices
产生原因 这个事件发生在 Kubernetes 无法更新 EndpointSlice 对象时。EndpointSlices 是 Endpoints 的升级版,用于存储 Service 后端 Pod 的网络端点信息。
常见原因:
- 网络问题:与控制平面通信中断
- 权限问题:Service Account 没有更新EndpointSlices 的权限
- 资源冲突:EndpointSlice 对象被锁定或损坏
- API 服务器过载:请求被拒绝或超时
资源占用
查看资源占用列表
| 字段 | 说明 |
|---|---|
| 发生时间 | |
| 资源类型 | |
| 资源对象 | |
| 资源占用情况 |
搜索资源占用事件
| 字段 | 说明 |
|---|---|
| 资源对象 | |
| 发生起止时间 |